前言
由于研究的主要是ELF文件,所以要对于ELF文件的底层实现要了解,要懂得ELF文件是如何从源代码一步步变成计算机所认识的机械码的。还有要了解ELF文件内部是如何分布的
一、程序的编译与链接
一个C语言程序的生命是从源文件开始的,这样高级语言的形式更容易被人理解。但是,要想在操作系统上面运行程序,每条C语句都必须被翻译为一系列的低级机器语言。最后这些指令按照可执行目标文件的格式打包,并以二进制文件的形式存放起来。也就是大家所熟知的exe文件、elf文件。只有弄懂了程序是什么,是如何来的,才能对于分析程序才会更加方便
下面重点以GCC的编译过程进行了解、学习
gcc是linux下面的默认的C/C++的编译器,它可以将C语言代码直接编译成二进制程序ELF。window下是.exe文件。通过gcc的编译过程可以更加了解生成一个可执行程序的详细步骤。
1. 编译过程
(1)首先编写一个c语言源代码
#include<stdio.h>
int main(int argc, char const *argv[])
{
printf("Hello word!\n");
return 0;
}
(2)利用gcc编译器,对源代码进行编译
gcc test.c -o test -save-temps --verbose
参数说明:
①
gcc test.c: 是对C语言程序进行编译②
- o test:是将程序另命令为test文件,默认情况下是会编译成一个(.out)的文件③
-save-temps:将编译过程中生成的中间文件保存下来④
--verbose:用于查看GCC编译下的详细工作流程
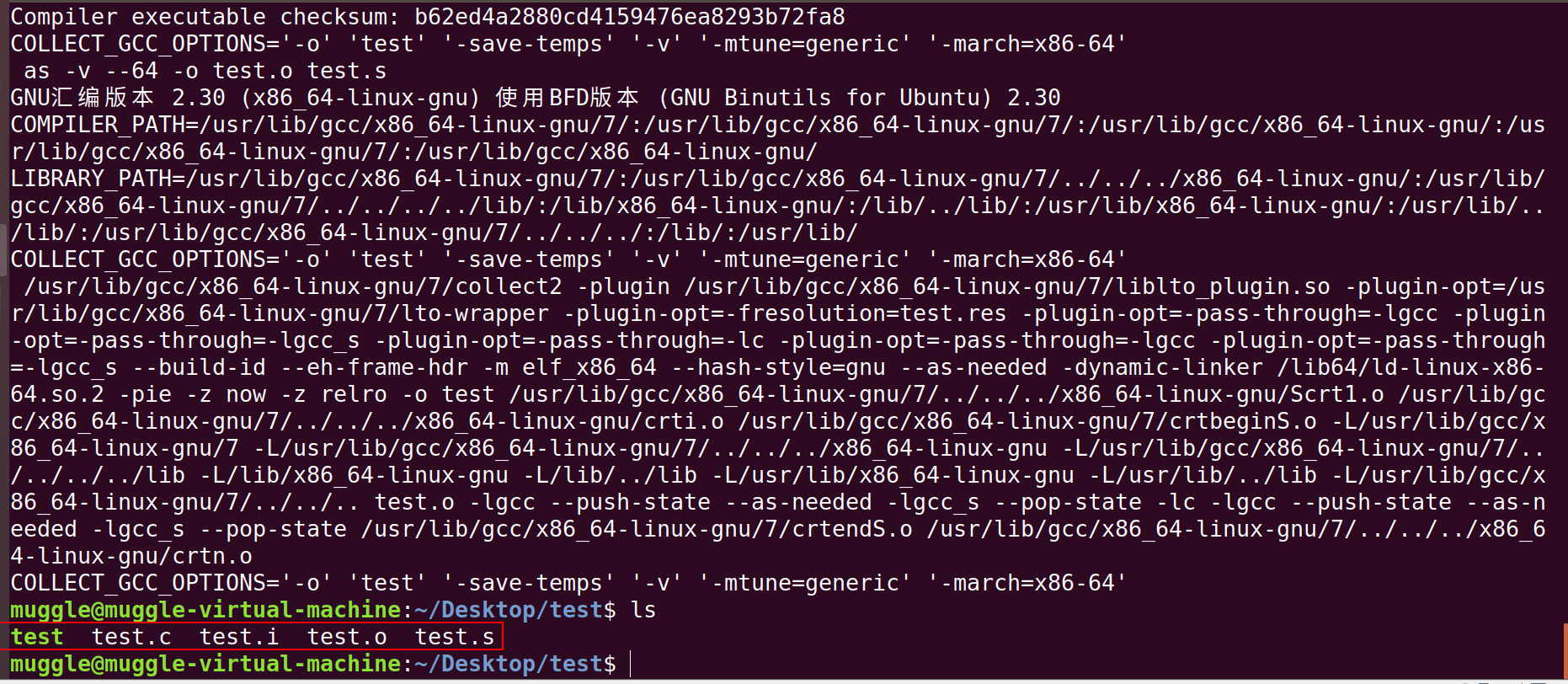
可以发现:
GCC的编译过程主要包括四个阶段:预处理阶段、 编译过程、汇编过程、链接过程。该过程分辨使用了ccl、as和collect2三个工具
① ccl是编译器:对应第一二个阶段,用于将源文件test.c ==》test.s
② as是汇编器:对应第三个阶段,用于将test.s ==》test.o
③ collect2是链接器,是对ld命令的封装:用于将C语言运行时库中的目标文件(前面的test.o文件)以及所需的动态链接库(libgcc.so、libc.so或是自己编写的等等 )链接到可执行文件hello
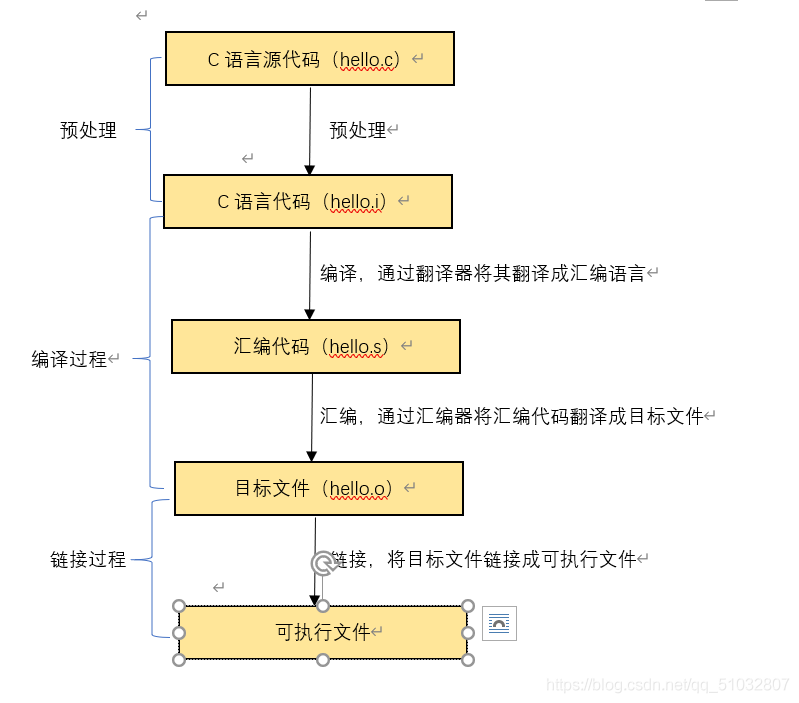
查看编译过程中的代码的变化:

2. 分析整个过程
2.1: 预处理
主要是处理源代码中关于 “#” 的预处理指令,通常以”.i”作为程序的扩展名
① 删除 # define,展开所有宏定义, 例如 #define x 1000
② 处理条件预编译指令:#if、#ifedf 、#elif、 #endif
③ 处理#include 预编译指令,将包含 “.h” 文件直接插在指定的位置
④ 删除掉所有的注释, /**/,//
⑤ 添加行号和文件名标识
在命令中添加编译选项 "-E" 可以单独执行预处理
gcc -E test.c -o test.i
此时可以通过编辑器可以查看文件的内容:(符合前面的预处理方式)
2.2:编译阶段
编译阶段就是对预编译的文件进行一系列的分析,最终生成汇编代码。
在命令中添加编译选项 "-S" 可以单独查看编译阶段,它通常以 .s 结尾
gcc -S test.i -o test.s
通过编辑器软件可以查看到里面的内容是一些汇编语言:

2.3:汇编阶段
汇编阶段主要就是汇编器根据生成的汇编指令与机械指令的对照表进行翻译,将test.s会变成目标文件test.o。
在命令中添加编译选项 "-c" 可以单独生成目标文件
gcc -c test.s -o -test.o
此时的目标文件是一个可重定位文件。并且无法执行此文件

通过编辑器打开该文件可以发现里面是一群十六进制组成的
此时的话可以通过objdump来查看文件的内容
objdump -sd test.o -M intel
参数说明:
-s:反汇编test.o中的需要执行指令的那些section
-d:反汇编,查看程序的十六进制和汇编指令
-M intel:使用intel格式,方便观看
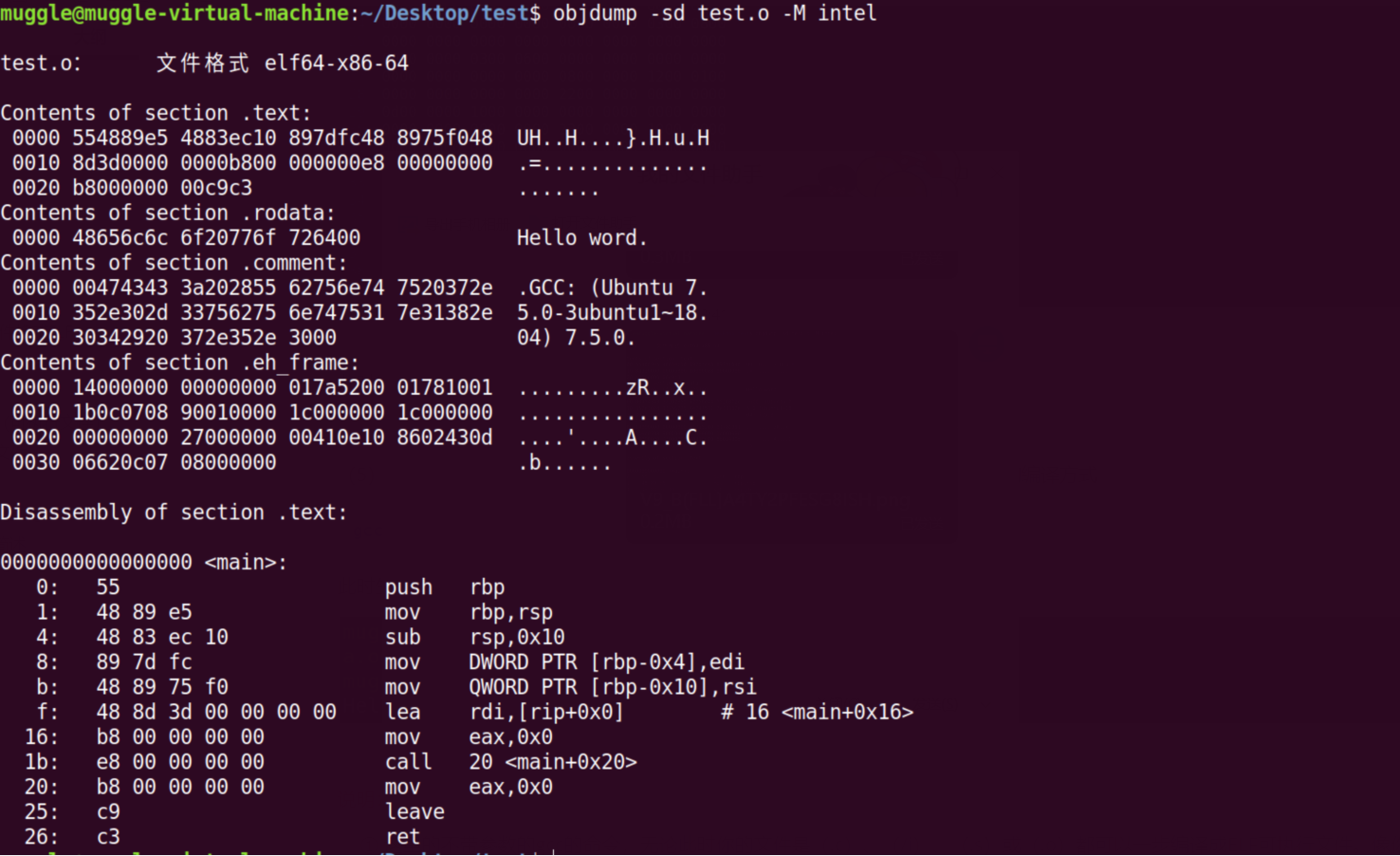
可以发现关于Hello word 的地址还被设置为00、而且函数printf的地址则指向为下一条指令的地址。这是因为程序还没有链接,无法程序识别printf函数,找不到对应的位置
2.4:链接过程
链接过程可使用静态链接或动态链接,这一阶段将目标文件(.o)和所依赖的库进行连接,生成可执行文件(.out)。如果没有链接过程就无法找到一些在库的函数的地址。
GCC默认使用动态链接,添加静态链接需要设置编译选项为 ”-static“
gcc test.o -o test -static
说明:编译时如果程序不另外命名,则会生成了一个后缀是(.out)的文件。此时运行发现可以出现结果

利用objdump查看此时生成的文件的汇编代码:
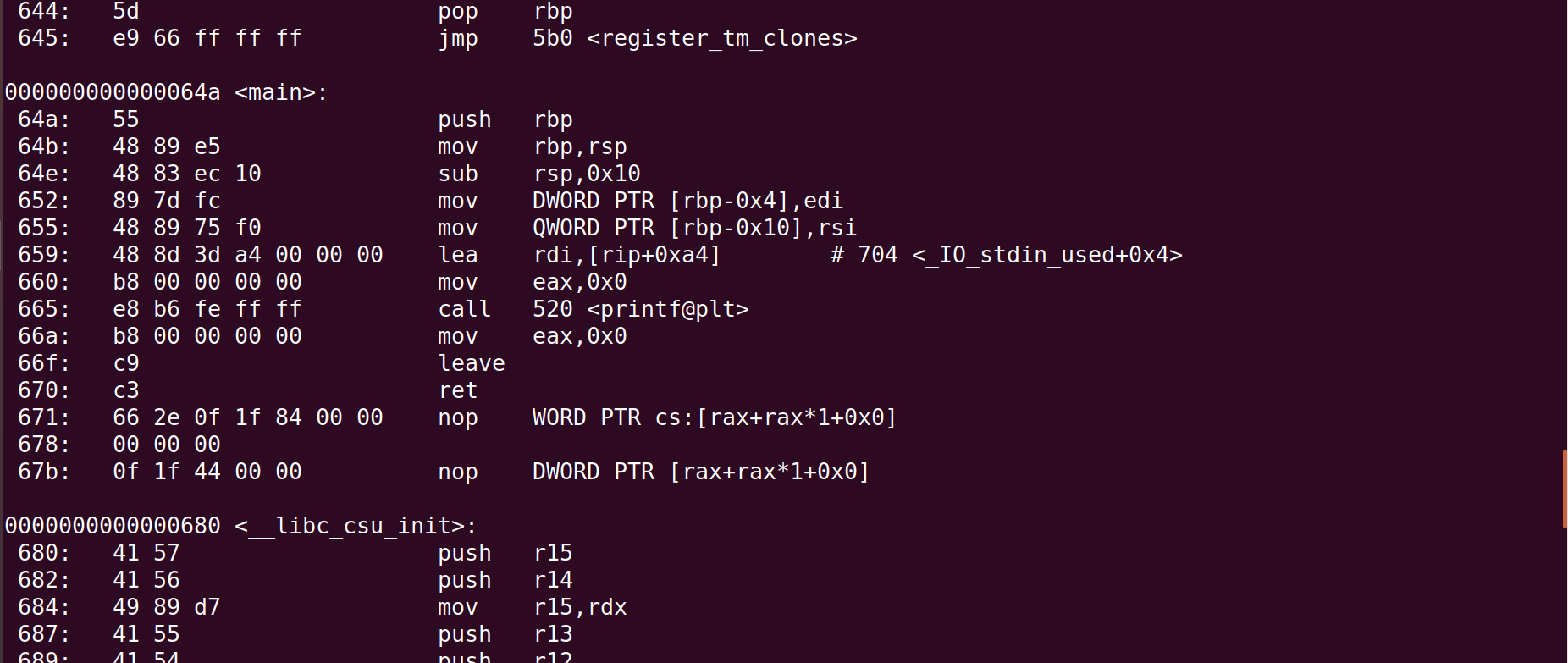
可以发现此时生成的printf函数的地址已经发生了改变,确定了printf函数的地址。通过链接过程,对象文件中无法确定的符号地址已经被修正为实际的符号地址。这样程序也就可以被加载到内存中正常执行了
动态链接与静态链接的概念
静态链接:是指编译链接时,把库文件的代码全部加入到可执行文件中,那么运行时也就不再需要库文件了。此时你objump分别查看两种情况下的可执行文件,你就会发现静态链接的文件包含了大量的库文件。
动态链接:是指在链接时仅仅只加入一些描述信息,而是等到程序执行时再从系统中把相应动态库加载到内存
二、ELF 文件格式
ELF,即”可执行可链接格式“,最初是作为应用程序二进制接口的一部分而指定发布的,linux系统上面所运行的就是ELF格式的文件。ELF文件又叫做可执行的二进制文件,可执行的二进制文件还有Windows的exe文件。
1. ELF文件的类型
ELF文件主要可分为三种类型:可执行文件(/exec)、可重定位文件(.rel)和共享目录文件
可执行文件: 经过链接的、可执行的目标文件。通常被成为程序,像前面的a.out文件
可重定位文件:由源文件编译而成但是还没有链接的程序,通常以
.o作为文件拓展名。 用于与其他目标文件进行链接以构成可执行文件或动态链接库。通常是一段独立的代码。像前面的test.o 文件共享目标文件:动态链接库文件。用来链接过程中与其他动态链接库或者是可重定位文件、或者是在可执行文件在加载时,链接到进程中作为运行代码的一部分。一般是xxx.so
特别说明:
在ELF文件格式规范中,ELF文件被统称为目标文件,而不单单是指 已经编译但是而为编译的文件(.o)。所以下面所有称为目标文件的都是指各种类型的ELF文件,而对于”.o“ 文件。则直接称它为 可重定位文件。 由于这类文件包含了代码和数据,可以用于链接成可执行文件或共享目标文件,所以对于分析ELF文件的格式是非常好的。
2. ELF文件的结构
在审视一个ELF文件时有两种视角可供选择:一是链接视角(即没有运行时的程序),它主要是通过节(Section)来进行划分;二是运行视角(即程序运行时的视角),它主要是通过段(Segment)来进行划分。
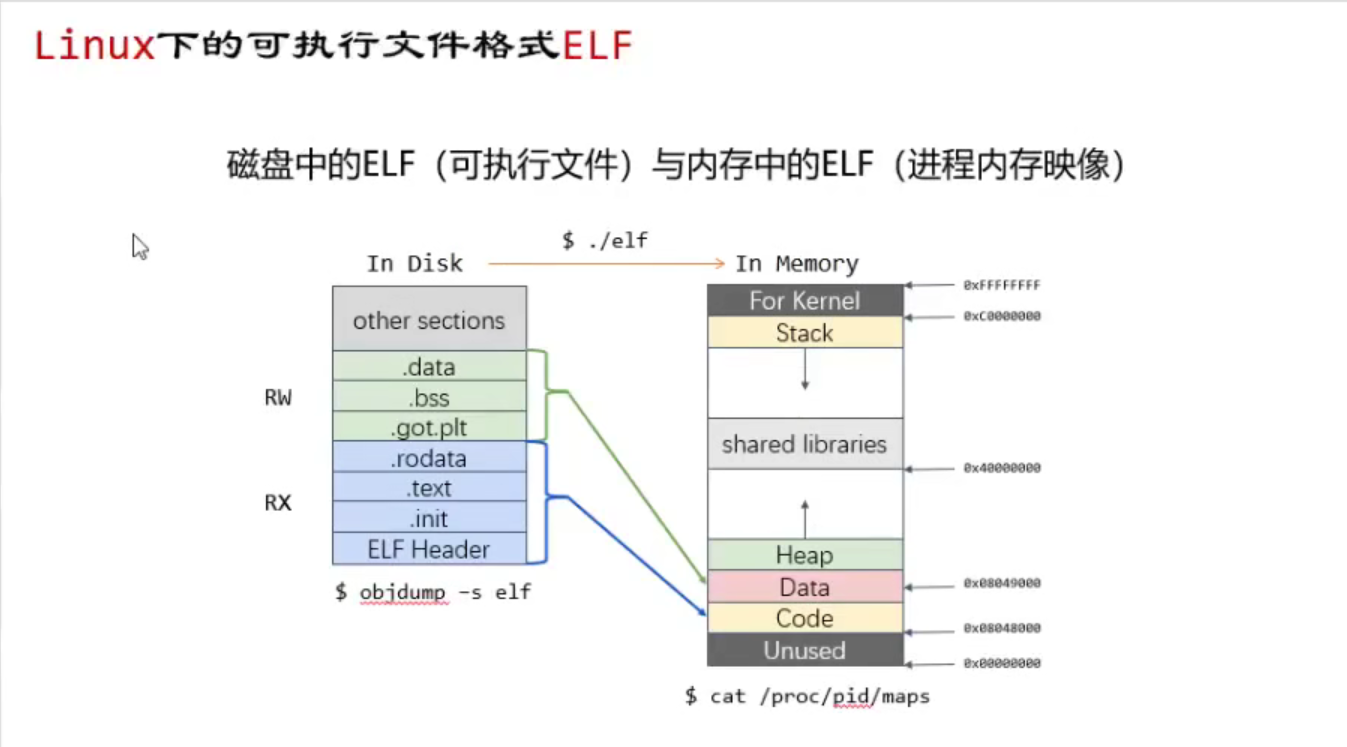
2.1:链接时的ELF文件
从链接视角看:它主要是由文件头(ELF Header)、程序头、节头(Section Header)表、符号表( Symbol Table)、动态符号表(Dynamic Symbol Table)等组成。
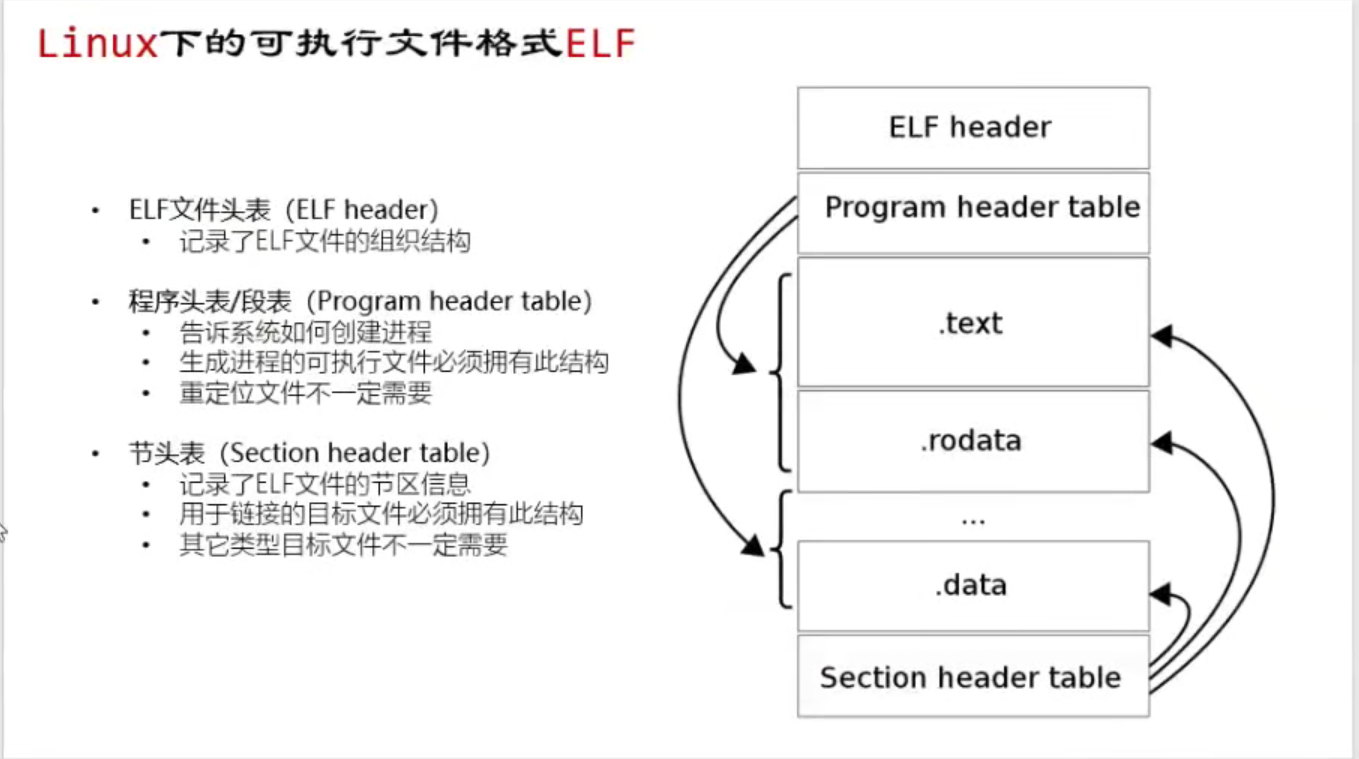
(1)ELF文件头
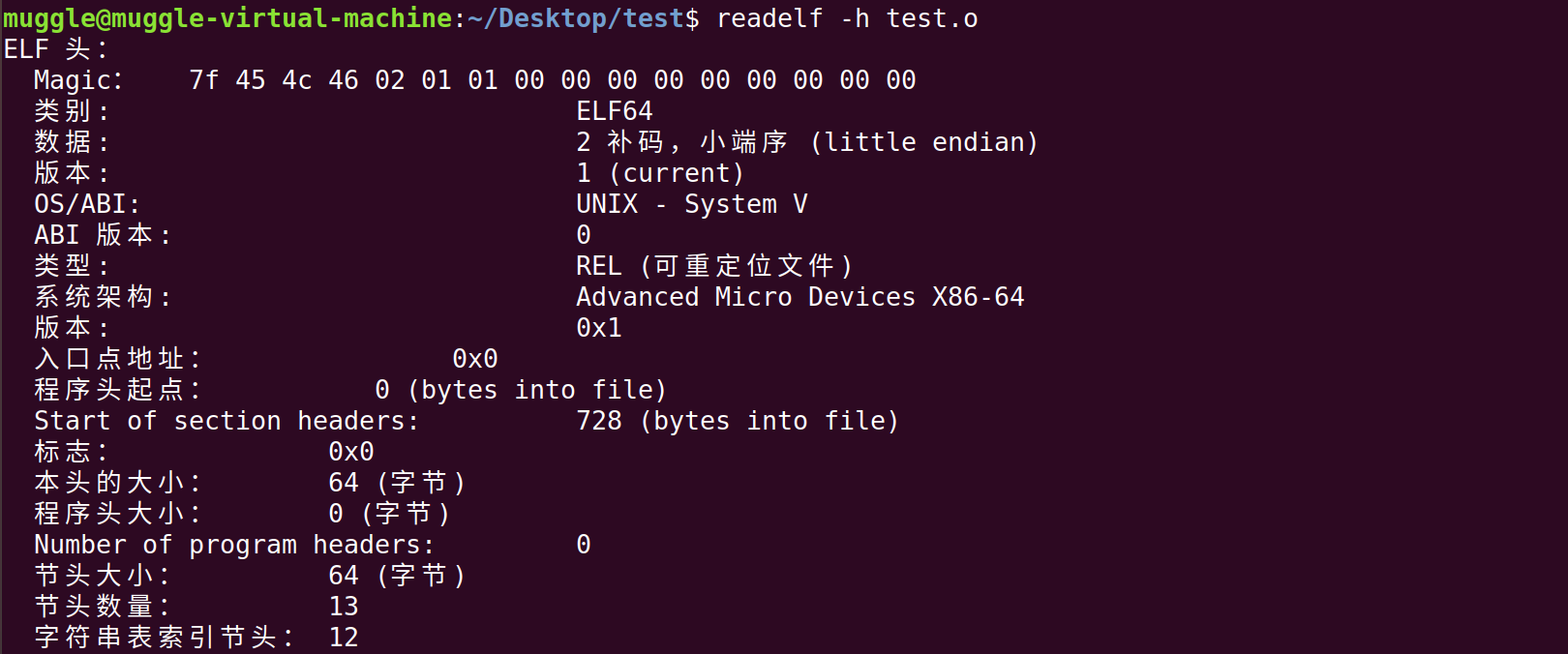
位于目标文件最开始的位置,包含描述整个文件的一些基本信息。例如:ELF文件类型、版本/ABI版本、目标机器、程序入口、段表和节表的位置和长度等。它的存在主要是给操作系统看的,操作系统通过分析这个头表为ELF文件建立一个进程意向
注意:文件头部存在魔术字符(7f 45 4c 46),即字符串”\77ELF”,当文件被映射到内存时,可以通过搜索该字符串确定映射地址,这在dump内存时非常有用
此时可通过readelf命令查看文件头的一些信息:
readelf -h test.o
(2)程序头
在可重定位文件中没有程序头,它主要是存在于可执行文件中和共享目标文件
(3)节头表
一个目标文件中包含许多节, 这些节的信息保存在节头表中。节头表对于程序的运行并不是必须的,因为它与程序内存布局无关,是程序头表的任务。所以常有程序去除节头表,以增加反汇编器的分析难度
记录了节点的名字、长度、便宜、读写权限等信息
通过readelf命令可以查看程序的节头表信息
readelf -S test.o
muggle@muggle-virtual-machine:~/Desktop/test2$ readelf -S a.out
There are 29 section headers, starting at offset 0x1928:
节头:
[号] 名称 类型 地址 偏移量
大小 全体大小 旗标 链接 信息 对齐
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000000238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000000254 00000254
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 0000000000000274 00000274
0000000000000024 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000000298 00000298
000000000000001c 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 00000000000002b8 000002b8
00000000000000a8 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000000360 00000360
0000000000000082 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 00000000000003e2 000003e2
000000000000000e 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 00000000000003f0 000003f0
0000000000000020 0000000000000000 A 6 1 8
[ 9] .rela.dyn RELA 0000000000000410 00000410
00000000000000c0 0000000000000018 A 5 0 8
[10] .rela.plt RELA 00000000000004d0 000004d0
0000000000000018 0000000000000018 AI 5 22 8
[11] .init PROGBITS 00000000000004e8 000004e8
0000000000000017 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000000500 00000500
0000000000000020 0000000000000010 AX 0 0 16
[13] .plt.got PROGBITS 0000000000000520 00000520
0000000000000008 0000000000000008 AX 0 0 8
[14] .text PROGBITS 0000000000000530 00000530
00000000000001a2 0000000000000000 AX 0 0 16
[15] .fini PROGBITS 00000000000006d4 000006d4
0000000000000009 0000000000000000 AX 0 0 4
[16] .rodata PROGBITS 00000000000006e0 000006e0
0000000000000010 0000000000000000 A 0 0 4
[17] .eh_frame_hdr PROGBITS 00000000000006f0 000006f0
000000000000003c 0000000000000000 A 0 0 4
[18] .eh_frame PROGBITS 0000000000000730 00000730
0000000000000108 0000000000000000 A 0 0 8
[19] .init_array INIT_ARRAY 0000000000200db8 00000db8
0000000000000008 0000000000000008 WA 0 0 8
[20] .fini_array FINI_ARRAY 0000000000200dc0 00000dc0
0000000000000008 0000000000000008 WA 0 0 8
[21] .dynamic DYNAMIC 0000000000200dc8 00000dc8
00000000000001f0 0000000000000010 WA 6 0 8
[22] .got PROGBITS 0000000000200fb8 00000fb8
0000000000000048 0000000000000008 WA 0 0 8
[23] .data PROGBITS 0000000000201000 00001000
0000000000000010 0000000000000000 WA 0 0 8
[24] .bss NOBITS 0000000000201010 00001010
0000000000000008 0000000000000000 WA 0 0 1
[25] .comment PROGBITS 0000000000000000 00001010
0000000000000029 0000000000000001 MS 0 0 1
[26] .symtab SYMTAB 0000000000000000 00001040
00000000000005e8 0000000000000018 27 43 8
[27] .strtab STRTAB 0000000000000000 00001628
0000000000000202 0000000000000000 0 0 1
[28] .shstrtab STRTAB 0000000000000000 0000182a
00000000000000fe 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
可以发现在节头表存储的是一些节,主要有:bss节、text节、.got.Plt表、data节、plt节等等,每一个节都有自己特定的功能
.bss段:bss段(Block by symbols)属于静态内存分配通常是用来存放程序中 未初始化的全局变量的一块内存区域
.data段:属于静态内存分配,通常是用来存放已初始化的全局变量的一块内存区域。
.text段: 通常是指用来存放程序执行代码的一块内存区域,这部分区域的大小在程序运行时就已经确定,并且内存区域通常属于只读(显然是不允许用户修改代码的)
.plt:包含了动态链接器调用从共享库导入的函数必需的相关的代码
.got.plt:全局偏移表,用于保存了全局变量引用的地址,got表就位于该节(这里用到了got表的劫持)
.rodata:字符串
.got: 全局偏移量表,用于保存全局变量引用的地址
下面通过objdump命令来具体的分析一下程序节头区里面的 .text(代码)节、.data(数据节)、.bss(BSS)节
objdump -xsd test.o
参数说明:
-x:显示所可用的头信息,包括符号表、重定位入口。-x 等价于-a -f -h -r -t 同时指定。
-s:显示目标文件的全部Header信息和他们对应的十六进制文件代码
-d:对目标文件进行反汇编由于test.o的文件未进行链接,可能对于分析节头区更加方便
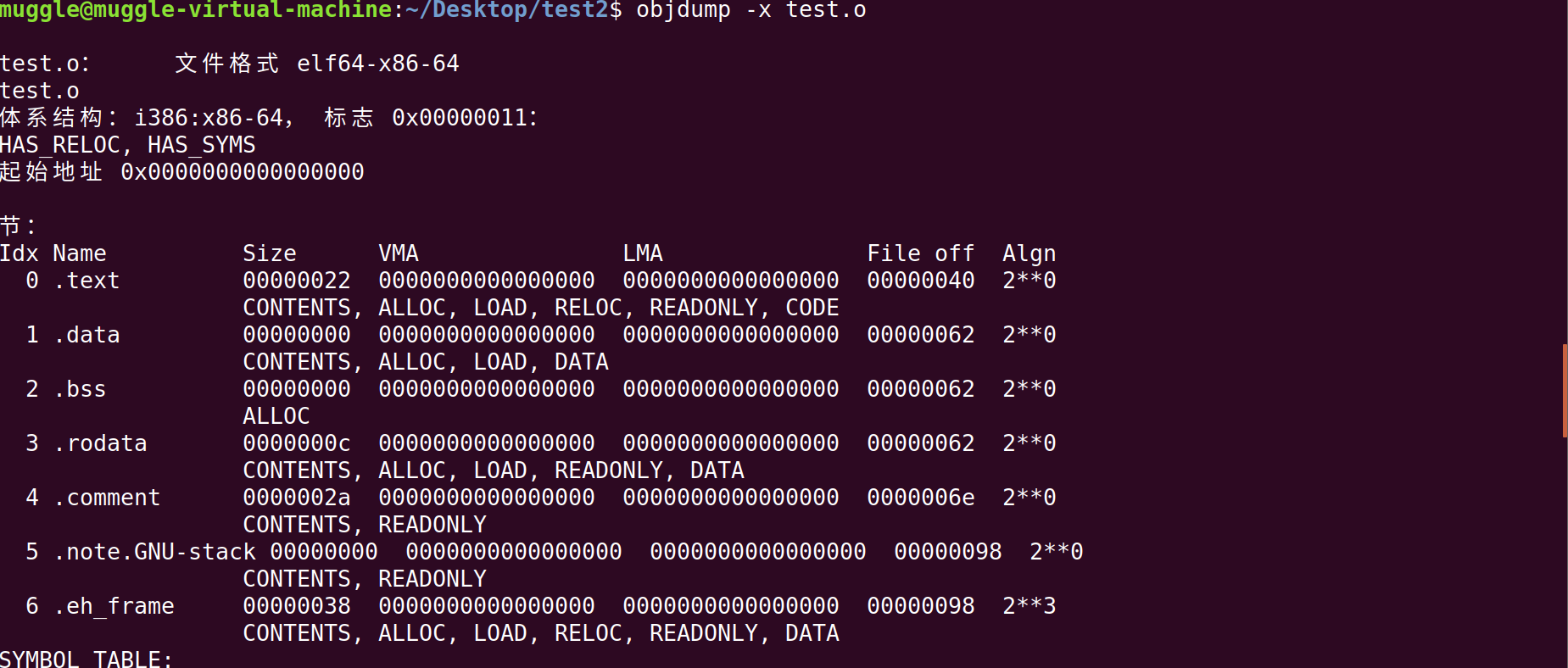

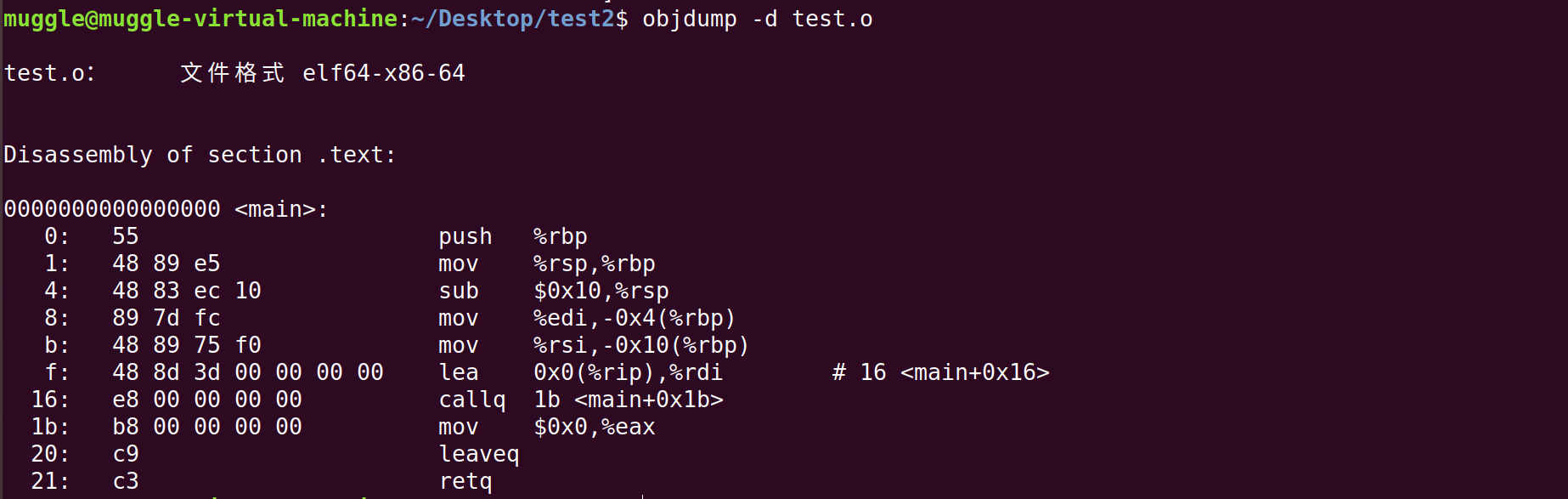
a. 首先查看程序的代码节:
节:
Idx Name Size VMA LMA File off Algn
0 .text 00000027 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
Contents of section .text:
0000 554889e5 4883ec10 897dfc48 8975f048 UH..H....}.H.u.H
0010 8d3d0000 0000b800 000000e8 00000000 .=..............
0020 b8000000 00c9c3 .......
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: 89 7d fc mov %edi,-0x4(%rbp)
b: 48 89 75 f0 mov %rsi,-0x10(%rbp)
f: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 16 <main+0x16>
12: R_X86_64_PC32 .rodata-0x4
16: b8 00 00 00 00 mov $0x0,%eax
1b: e8 00 00 00 00 callq 20 <main+0x20>
1c: R_X86_64_PLT32 printf-0x4
20: b8 00 00 00 00 mov $0x0,%eax
25: c9 leaveq
26: c3 retq
可以看到Contents of section.text部分是.text数据以十六进制的形式展示,共有十个字节,其中最左边一列是偏移量,中间四列是内容,最左边一列是ASCII码形式。而 Disassembly of section .text 是反汇编以后的结果
b. 然后查看程序的数据节和只读数据节
节:
Idx Name Size VMA LMA File off Algn
1 .data 00000000 0000000000000000 0000000000000000 00000067 2**0
CONTENTS, ALLOC, LOAD, DATA
3 .rodata 0000000b 0000000000000000 0000000000000000 00000067 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
Contents of section .rodata:
0000 48656c6c 6f20776f 726400 Hello word.
可以看到.data保存已经初始化的全局变量和局部变量静态
.radata节:保存了只读数据,包括只读变量和字符串常量。源代码中调用printf函数时,用到了一个字符串,它是只读数据包,因此保存在.rodata节当中,而且字符串是以ASCII形式展示的
c. 最后看.bss节
节:
Idx Name Size VMA LMA File off Algn
2 .bss 00000000 0000000000000000 0000000000000000 00000067 2**0
ALLOC
用于保存未初始化的全局变量和局部静态变量。此时还可以发现该节段没有CONTENTS属性。这表示该节在文件中实际并不存在,只是为变量预留了位置而已。
(4)符号表
符号表记录了目标文件中所用到的所有符号信息,定义的符号 。通常分为 .dynsym 和 .symtab
① dynsym 是 .symtab的子集
② .dynsym 保存了引用外部文件的符号,只能在运行是被解析
③ .symtab 除了dynsym 的功能,还保存本地符号, 用于调试和链接
目标文件通过一个符号在表中的索引值来使用该符号。索引值从0开始计数,但是值为0 的表项不具有实际的意义, 它表示未定义的符号。每一个符号都有一个符号, 对于变量和函数,该值就是符号的地址
重定位:
重定位是连接符号定义与符号引用的过程。可重定位文件在构建可执行文件或共享目标文件时, 需要把节点的符号引用换成这些符号在进程空间中的虚拟地址。
包含这些转换信息的数据就是重定位项。
2.2:运行时的ELF文件
下面成运行的视角来审视ELF文件。
当运行一个可执行文件时,首先要将文件和动态链接库装载到进程空间中,形成一个进程镜像。每个进程都拥有独立的虚拟地址空间,这个空间如何布局是由记录在段头表中的程序表来决定的。
打开gdb调试页面。查看内存。你主要看到的是code(代码段)、Data(数据段)、stack(栈)、heap(堆)
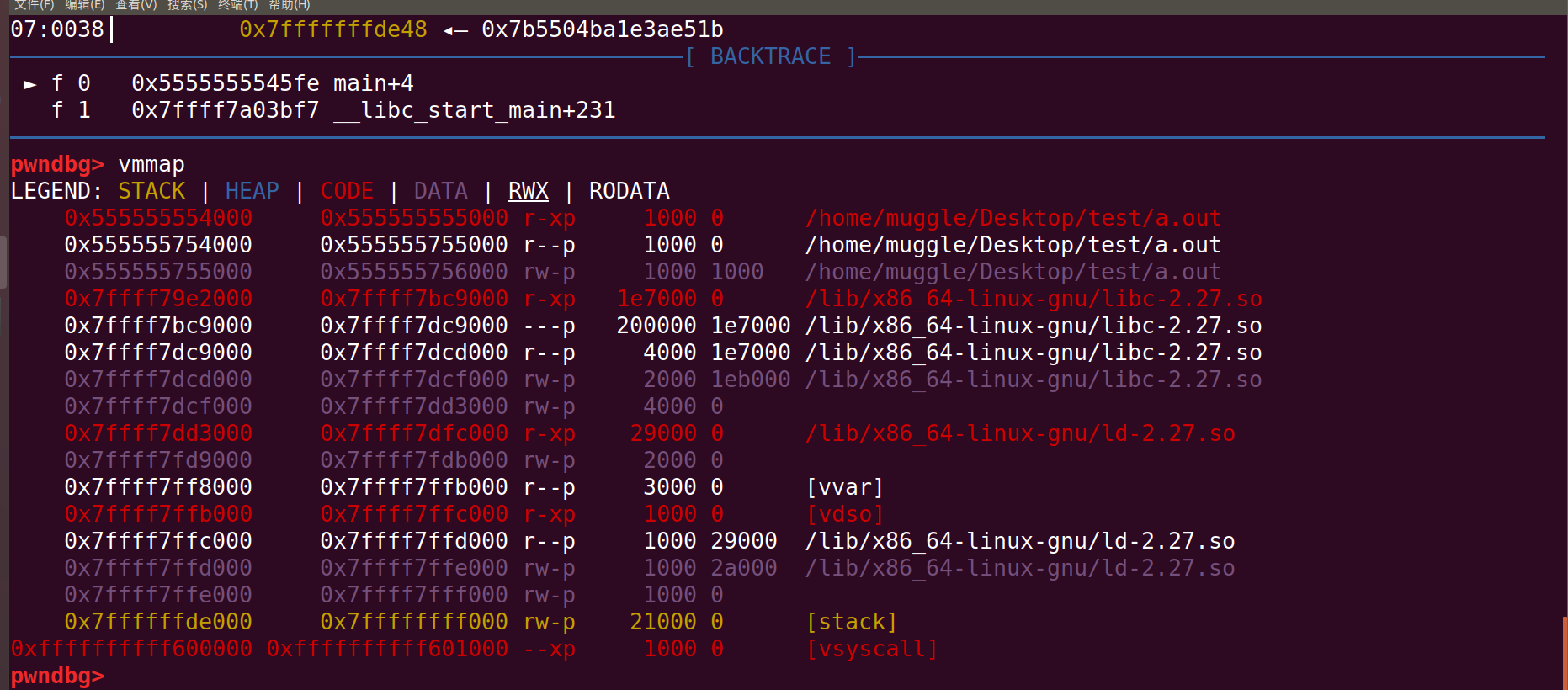
.data .bss .got .plt ==》数据data段、这些机械码在执行中所用到的相关的数据
.rodata .text .init ELF header ==》code代码段(不可写的)、、cpu认的机械码
stack:用来管理里面函数调用的状态
heap:用来给用户提供内存,动态内存申请的调用
比如:malloc一大块内存,在大块内存里面放一个图片,这个图片并没有写死在这个可执行文件里面的,所以只能在内存的进制空间里面再开辟一块内存,在heap里面提供给用户的malloc的内存,再heap里面存放图片。图片同样在内存的可执行文件的对应的虚拟内存空间当中,但是并不存在在磁盘的可执行文件当中
gdb:低地址往高地址写,出于写数据的原因,gdb的低地址在上面
三、 静态链接与动态链接
链接:主要就是通过链接器将两个或者是多个不同的目标文件组合成一个可执行文件。然后根据时间不同又可分为:编译时链接、加载时链接和运行时链接
1. 静态链接
由于静态链接存在的一些缺陷以及当前默认是动态链接的,所以对于静态链接的方式我只是做个了解。不过如果pwn中出现的题目是用静态链接的方式链接的,而且程序的溢出大小很大,那么就可能通过特殊的方法一键获取flag
下面存在两个C语言文件来简单实现一下程序之间是如何链接的
main.c
#include<stdio.h>
extern int shared;
extern void func(int *a, int *b);
int main(int argc, char const *argv[])
{
int a = 100;
func(&a, &shared);
return 0;
}
func.c
#include<stdio.h>
int shared = 1;
int tmp = 0;
void func(int *a, int *b){
tmp = *a;
*a = *b;
*b = tmp;
}
通过gcc编译将两个目标文件链接成一个可执行文件
gcc -static -fno-stack-protector main.c func.c -save-temps --verbos -o func.elf
最终可以得到这么多文件

链接方式主要有两种
第一种方法:按序叠加
就是按照程序的执行顺序进行叠加在一起。比如先执行,main.o源代码,从文件头->text->.data->.bss ==》func.o
这种方法的弊端:
① 参与的链接的目标文件过多,那么输出的可执行文件会非常零散。
② 段的装载地址和空间以页为单位,不足一页的代码节或数据节也要站一页,造成内存空间的浪费
第二种方法:相似节合并
将不同目标文件的相同属性的节合并为一个节,如将main.o和func.o的text节合并为新的.text节。
方式:先对各个节的长度、属性和偏移进行分析,然后将输入目标文件中符号表的符号定于i与符号引用同意生成全局符号表,最后读取输入文件的各类信息对符号进行解析、重定位等操作。相似节的合并就发生在重定位时。完成后,程序中的每条指令和全局变量就有唯一的运行内存地址了
2. 动态链接
由于静态链接是直接把需要的代码直接链接上去,显然对于内存是一种负担。于是就出现了动态链接
动态链接:在运行或者是加载时,在内存完成链接的过程。
==》 把系统库和自己编写的代码分割成两个独立的模块,等到程序真正运行时,再把两个模块进行连接。
那么对于上面的两个源代码如何采取动态链接的方式的呢?
首先要将func.c这个代码编译成共享库文件,然后使用这个库编译main.c。
gcc -shared fpic -o func.so
gcc -fno-stack-protector -o func.elf2 main.c ./func.so
参数说明:
-shared:表示生成共享库
-fpic: 表示生成与位置无关的代码
这样可执行文件func.elf2 就会在在加载时与func.so进行动态链接
注意:
动态加载器ld-Linux.so本身就是一个共享库,因此加载器会加载并运行动态加载器, 并由加载器来完成其他共享库以及符号的重定位
通过ldd查看此时的ELF文件, 可以发现此时的文件已经链接好了 func.so库了, 除此之外还有一个ld-linux.so库
ldd func.elf2

用objdump查看汇编代码
objdump -d -M intel --section=.text func.elf2 |grep -A 11 "<main>"

可以发现自己制作的func.so动态链接库已经被链接成功了
说明:
一个程序(或者是共享库)的数据段和代码段的相对距离总是保持不变的
⬇⬇⬇⬇⬇⬇⬇⬇⬇
指令和变量之间的距离是一个运行时常量,与绝对内存地址无关。
⬇⬇⬇⬇⬇⬇⬇⬇⬇
于是就有了全局偏移表(GOT),它位于数据段的开头,用于保存全局变量和库函数的作用,每个条目占8个字节,在加载是会进行重定位并重写符号的绝对地址、
实际上
为了引入:RELRO保护机制,GOT表被拆分为 .got节 和 .got.plt 节两个部分,
.got节: 不需要延迟绑定, 用于保存全局变量引用,加载到内存后标记为只读
.got.plt节:需要延迟绑定, 用于保存函数引用,具有读写权限
查看func.so的情况
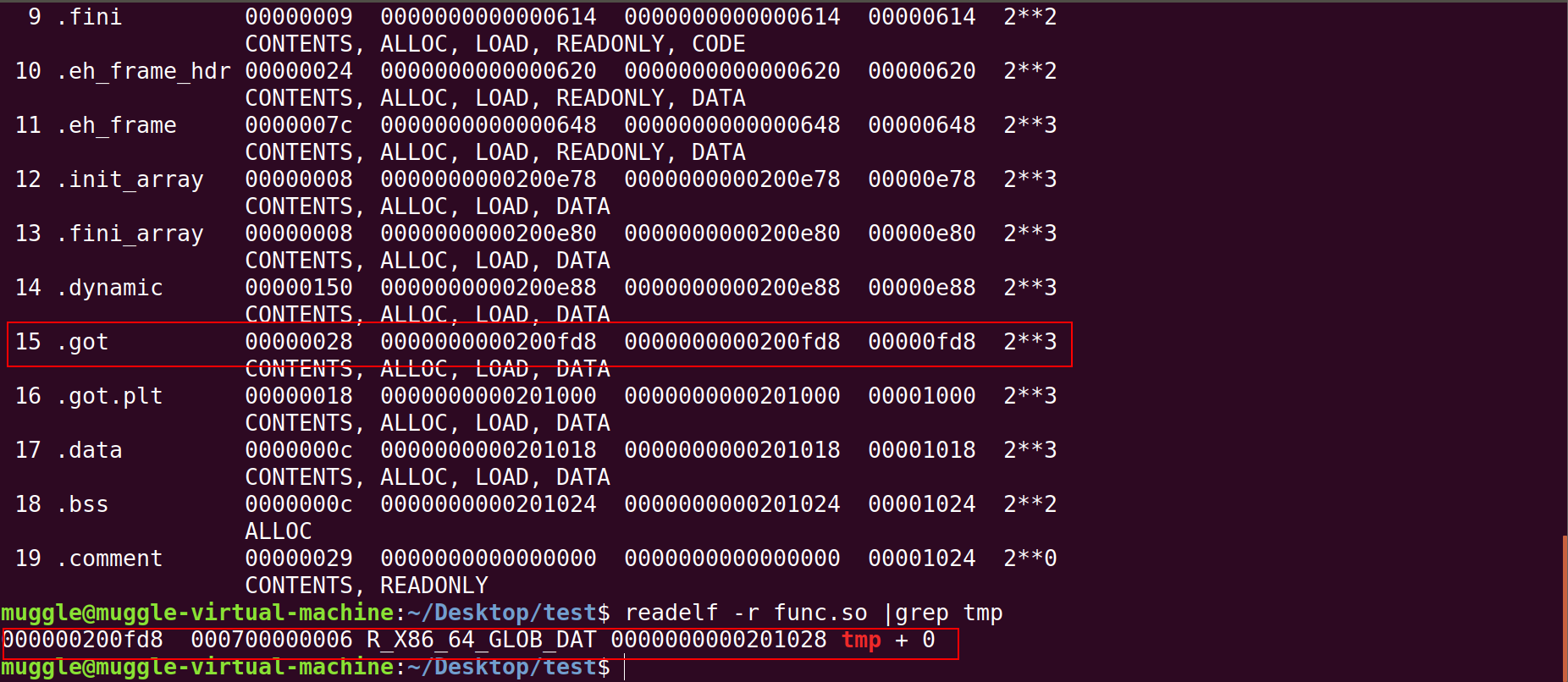
可以发现:
全局变量位于 GOT上, R_X86_64_GLOB_DAT表示需要动态链接器找到tmp的值并填充到0x200fd8。
在func()函数需要取出tmp是,计算符号相对于PC的便宜 rip + 0x20090, 也就是 0x6c9 + rip+0x2008a5z= 0x200fd8
rip+0x2008a5
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮箱至 1627319559@qq.com

